Nodes of Yesod : ZX Spectrum Next : Update #4
A Big Change Of Plans!

Astro Charlie has a close encounter
If you have read my previous updates, you’ll know that Nodes of Yesod for the Speccy Next is based on a C codebase. I’ve discussed details of my progress in that direction in previous posts, tool selection, and various other considerations.
I have to share with you that I’ve had a rethink and there’s a big change of plans!
As I intend to make this version of Nodes freely available, and since it follows that there’s no direct benefit to me financially, building the game has to be a fun and enjoyable endeavor. While I’ve enjoyed certain aspects of getting a C codebase to compile and run on the Next, I’ve had a few nagging doubts. C was always going to be a ‘heavy’ way to do things on an 8-bit Z80 (even with a faster clock), and paging code in and out of 8K or 16K banks does not make things less complicated; however, more than that, I need to personally get something out of this, it needs to be a fun process, and I want to write some Z80 code!
What’s The Plan?
Let me take you back in time. In 2003 I purchased a full version of IDA Pro from Hex-Rays, version 4.5.0.762. Perhaps I’ll cover the specific use case for that purchase in a future post, but suffice to say there were a couple of 8-bit and 16-bit games I wanted to disassemble. And IDA Pro was the best possible disassembler tool available at that time.
IDA stands for ‘interactive disassembler’, which is what the tool does. A disassembler can be compared by analogy to a tool into which you could feed a cake, whereupon it will output the ingredients for that cake. Eggs, sugar, flour, etc. An ‘interactive’ disassembler can go much further and give you not only the ingredients but also the recipe for that cake, along with baking instructions. IDA happens to be extraordinarily good at this.
With IDA, you take a binary program (for example a memory dump of a Sinclair Spectrum game), load it into the disassembler, and then interactively recreate the program symbols, functions, branches, data areas, and data types that were present in the original source code (which may have been lost forever, as is the case for Nodes of Yesod). When a memory location is identified as a variable, ‘health’ for example, you can designate that memory address as a named ’label’, and then IDA automatically changes any references to that memory location into a reference to that label. The same with functions, IDA will change any subroutine call into a call to a named label.
I’ve used this fantastic tool for various projects, but I have never upgraded it because, in addition to being extraordinarily good at what it does, it is extraordinarily expensive (it’s about $2,000)!
One thing I have done, in the intervening years, sporadically, is to create a disassembly of Nodes of Yesod, which I’d guess is 90% plus complete. Not 100%, but close. You may be able to see what is coming at this point - I’m going to upgrade IDA Pro to the latest version (the original version is a DOS program) and complete the disassembly, right?
Wrong!
I’m not about to spend $$$ on the current version of IDA Pro (though did flirt with the idea!) but there is an alternative.
Ghidra
Ghidra, interactively disassembling Nodes of Yesod
If one thing is certain, it is that there is no certainty in life. While it was not certain that I could do what I wanted to do, I spent a couple of weeks evaluating Ghidra to continue the disassembly of Nodes (‘continue’ meaning ‘start over’ using the disassembly generated in IDA Pro as a guide) and things seemed promising, there appeared to be light at the end of the tunnel. Or else, there was a train headed my way and I was about to be flattened!
Ghidra is an interesting beast, in some ways similar to IDA, but open source. It is a creation of the NSA (yes, that NSA), and it is used to find vulnerabilities in binary code that is out in the wild, and to dissect malware. It’s probably used to create malware too if we’re honest. It is sophisticated, and I needed a mere fraction of its capabilities. For example, as you interactively disassemble binary code, Ghidra creates a C-like implementation of each function which could, theoretically, be used to reimplement the binary code in C. I did not need anything like that, I merely needed the Z80 disassembly, with the goal of generating a buildable set of source code. Would it be possible?
The Benefits
With this approach, I’d end up, if all went to plan, with a complete source code representation of Nodes. Not the original source code, but something that I could assemble with modern-day tools. From there, I could start to support Next-specific changes needed to make the updates I want. Additionally, it’d allow me to start from a point of a working game, and then add to it. For example, replacing the sprites with hardware sprites while having a playable game. And, I’d be able to debug the Z80 code directly without the additional C abstractions getting in the way.
But there would be other benefits. I’d like to publish the source code for the original, unmodified game. And, with an assembly source code version of the game, it would make it easier to target other 8-bit or 16-bit systems machines that never had a version of Nodes. NES perhaps? I’ve never developed for the non-Z80 8-bitters so that might be an interesting challenge. And if this works out, I could potentially do the same with other Speccy games. For example, I have a substantially complete disassembly of Crosswize, again in IDA Pro.
Another benefit would be that by starting with a complete disassembly of the original game, it would be possible to release a new version of Nodes for the Next sooner and incrementally release upgrades. That appeals to me because I’d be able to get software into peoples’ hands sooner.
What’s Stopping Me?
Creating a complete disassembly of anything is a ton of work, but that is not something I find offputting. As I said, it was not 100% certain I could generate the buildable source code I need from Ghidra. After diving into the disassembly, and doing a few experimental exports, I had yet to prove that the output was viable, meaning I could feed it into a tool like SNasm and get out of SNasm something identical, or at least very similar, to the original Nodes binary.
So Where Are We At?
TLDR, it’s done! I have 100% completed the disassembly of Nodes of Yesod, wrote an output formatter for Ghidra, in Python, that generates SNasm compatible source code with no hand modifications, assembled that code with SNasm, and created a binary identical to the one I started disassembling! And, it works! Here is the resultant binary running in CSpect (with commentary by yours truly).
The first time Nodes has built from Z80 source in over 30 years!
What Was Involved?
More than I thought! Ghidra is great at interactively disassembling and patching binary files. But I found generating an actual assembly language source code file tricky. And, there are bugs on the Z80 side that cannot be worked around, completely missing parentheses on some instructions, incorrect disassembly of other instructions, left or right parenthesis missing on other instructions, and so on. And the output it does generate doesn’t seem standard to me at all. So I wrote a Python (Jython) script to fix all these deficiencies, and more besides! Here’s what my ‘Listing’ script does, in no particular order:
- Generates an equates table at the top of the source file
- Outputs all equate definitions and references in ALL_CAPS to distinguish equates
- Fixes all the disassembly errors encountered so far, including bit/res/set (hl), jp (hl)/(ix)/(iy), add ix,iy, and more. These fixes should be in the core disassembler but they’re fixed at the point of generating the listing, for now.
- Honors function and end-of-line comments and outputs them into the source
- Co-opts two of the Ghidra comment modes (pre and post comments) to output pseudo assembler instructions into the code (this could be expanded but is functional for now):
opt z80
device zxspectrum48
org $5b00
- Adds a trailing colon to labels
- Formats hexadecimal numbers in SNasm format ($0000)
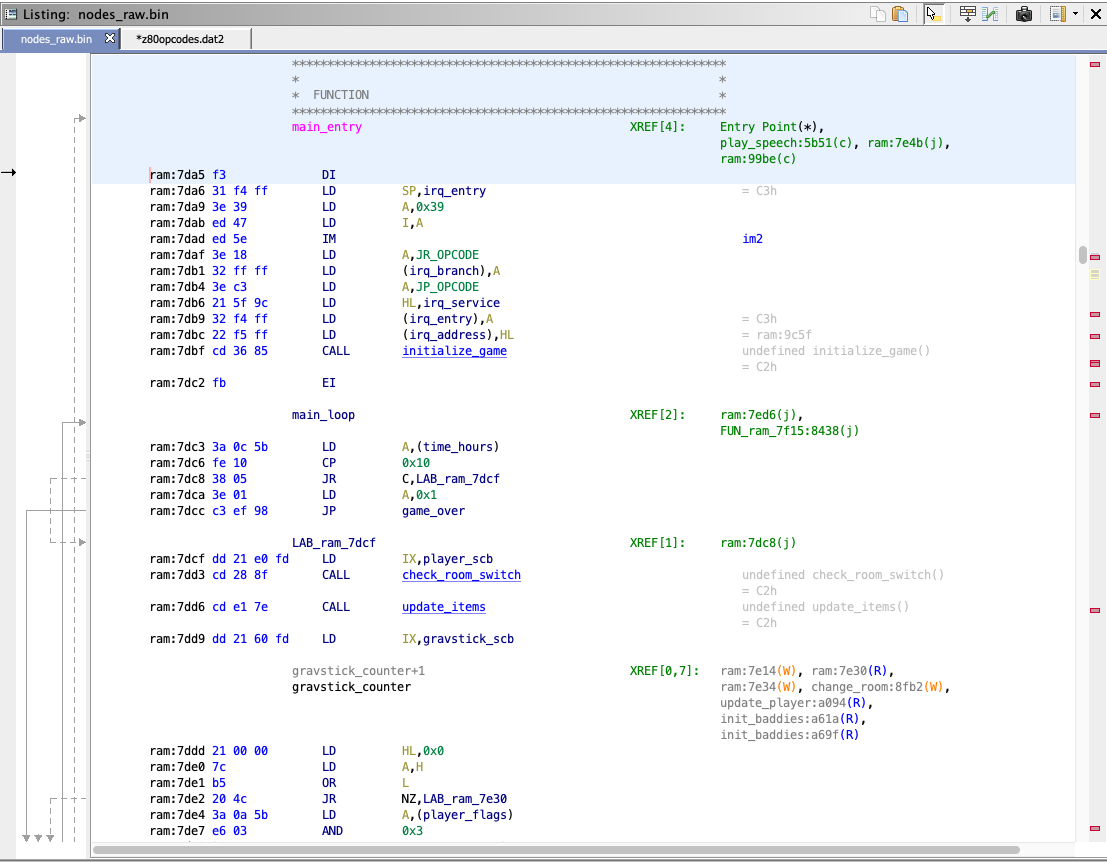
Here’s some actual output from the tool (it is the same area of code as the Ghidra screenshot above):
main_entry:
di
ld sp,irq_entry
ld a,$39
ld i,a
im 2 ; im2
ld a,JR_OPCODE
ld (irq_branch),a
ld a,JP_OPCODE
ld hl,irq_service
ld (irq_entry),a
ld (irq_address),hl
call initialize_game
ei
main_loop:
ld a,(time_hours)
cp $10
jr c,lab_ram_7dcf
ld a,$01
jp game_over
lab_ram_7dcf:
ld ix,player_scb
call check_room_switch
call update_items
ld ix,gravstick_scb
gravstick_counter:
ld hl,$00
ld a,h
or l
jr nz,lab_ram_7e30
ld a,(player_flags)
and $03
Perhaps it goes without saying that getting the code to output in the above format took hours of poring over Ghidra docs, figuring out their Jython scripting stuff, trying stuff out, falling flat on my face, rinse, repeat. There is no debugger (error logging FTW) and there’s not even a text search facility in the script editor. It is pretty gnarly, though the interactive Python console was very helpful, from there you can introspect objects and get interactive help on things. Got there in the end though!
What’s Next?
I have a small list of improvements that I want to make to the Listing script, including sorting the equates numerically into groups after renaming them with a
For example:
SPRITE_Y equ 2
SPRITE_X equ 1
SPRITE_DRAWH equ 15
ENEMY_THING equ 3
SPRITE_WIDTH equ 3
SPRITE_DRAWL equ 14
Becomes
ENEMY_THING equ 3
SPRITE_X equ 1
SPRITE_Y equ 2
SPRITE_WIDTH equ 3
SPRITE_DRAWL equ 14
SPRITE_DRAWH equ 15
Pretty obvious, but at the moment the equates appear in the order they were originally defined, which is basically random (and irritates me every time I see it).
Once these quality of life improvements are complete, I will then spend a little more time improving the comments in the disassembly, and adding symbolic names to the various places where the exact function still needs to be determined. Basically, I want to get the automatically generated source to be as good as practically possible before embarking on modifications for the Speccy Next.
I do hope to make this disassembly available on my Github in due course. I will also make my Ghidra listing script available, should any budding reverse engineers or code archeologists wish to review it (it’s not pretty and it is not clever but gets the job done).
I may also make an interim version of Nodes of Yesod available at that point, prior to embarking on the various planned improvements for the Spectrum Next version.
Hopefully, I’ll have an update within the next couple of weeks once all the groundwork listed above is done.
Onwards!
Addendum
i. To those wondering why I don’t use the original source code, the answer is simple: it, along with all other source code pre-1992, was ’lost’. Perhaps I will cover that in a future post.
ii. Yes, it has taken me longer to get to this point than it took to write the original game! My hope is that this effort will pay off and the approach can be applied to other games in the future.
If you enjoyed this, I'm writing something much deeper on Substack. A serialized memoir. Free to read.
Subscribe on Substack →Join the conversation
Comments are open on my Substack. Paid subscribers can leave notes, reply to posts, and join the community discussion.
Prefer the open web? Find me on Mastodon. I read everything and reply.
Comments (archived from the original blog)